Module 2 Principles of data science
What is data science?
Data science is an interdisciplinary field. Some have argued that it is not a field unto itself, but rather an extension of statistics. In this course, however, we’ll take the majority view that data science is its own field: a new field, which combines statistics, mathematics, and computer science.
But we’ll go one step outward. Data science is not just the combination of those academic disciplines which form its core; its also something more. Good data science involves domain knowledge (ie, familiarity with the problem being solved), effective communication, an iterative mentality (ie, creating feedback loops for rapid hypothesis testing), a bias to real-world effects rather than theoretical frameworks, and a willingness/desire to work in the real world.
There are a lot of Venn diagrams and figures out there, trying to show what data science is. For example…
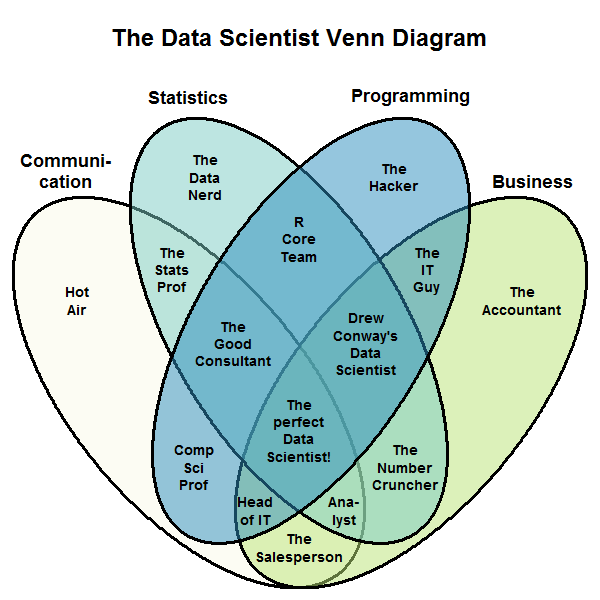
… or …
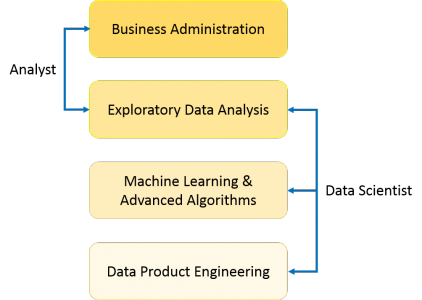
… or …
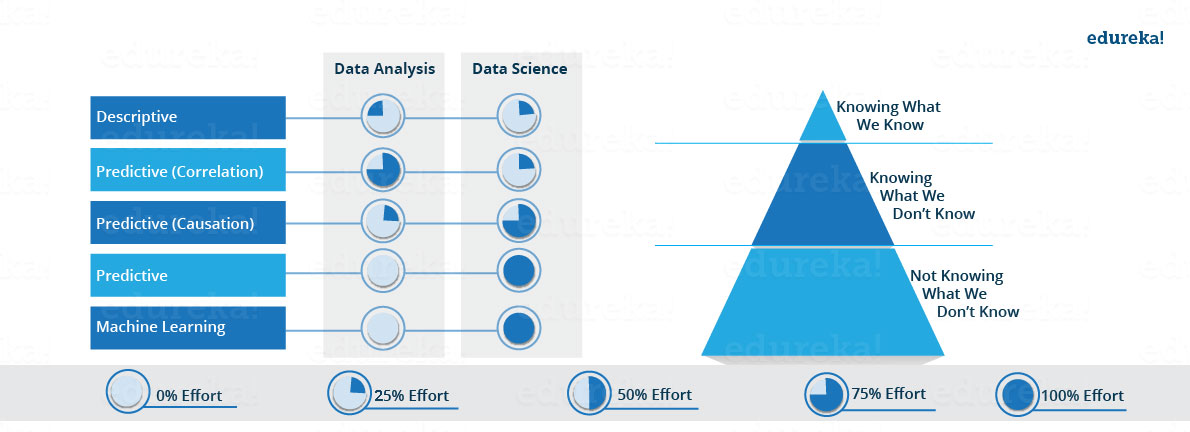
… or …
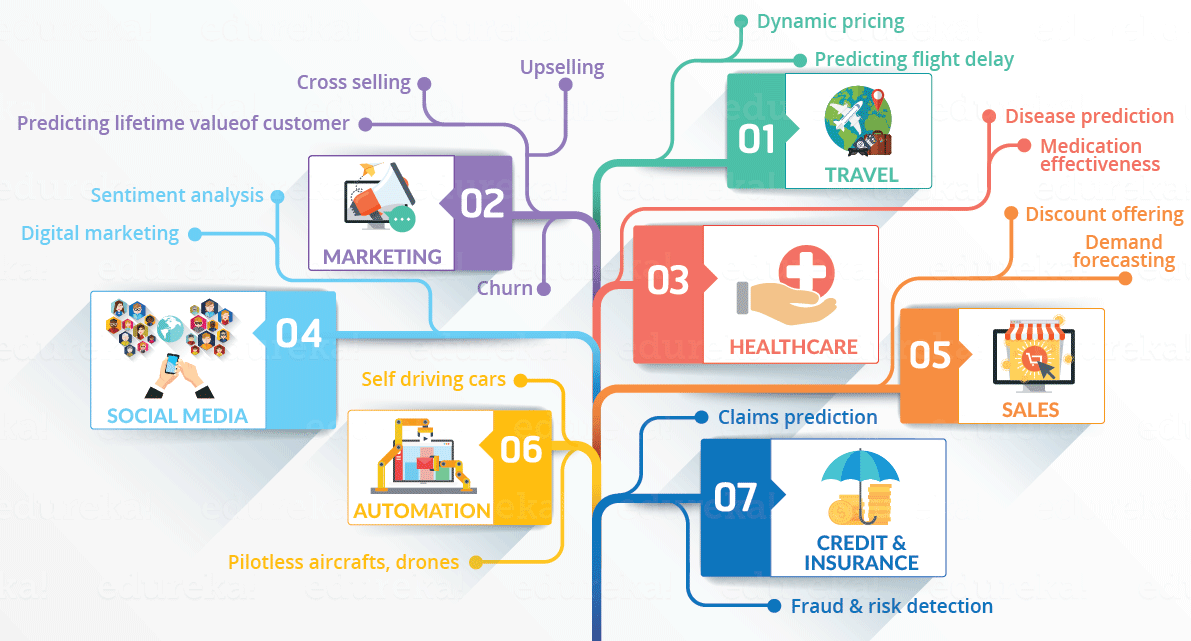
… or …
Our take? These are useful, interesting, and to some degree accurate but data science is too new, and too fluid, to be fixed into some static definition. 15 years ago, data science was “dashboards” and “predictive analytics”. 10 years ago, data science was “big data” and “data mining”. Since then, machine learning and artificial intelligence have taken up an ever-larger chunk of what most people consider data science. And in 5 or 10 years? Who knows.
So, to keep our definition accurate, we’ll keep it broad. Data science is simply “doing science with data”. And for our purposes, the only difference between our definition and the definition of science itself is not in the word “data” (since nowadays all scientists are, to some degree, “data scientists”), but rather in the word “doing”. Data science is about doing stuff with data. And that’s what this course is going to be about. DOING.
Data scientist vs data analyst vs data engineer
There is a lot of fuss out there about what constitutes data science and what doesn’t. Our definition is broad enough to encompass lots of things. So, we consider an “analyst” working in business intelligence to be a data scientist; and so too do we think that a data scientist could be an engineer who is processing large amounts of data to extract basic trends. Again, data scientists are those who do science with data. That’s a lot of people.
What is the data life cycle?
There is a misperception about data science work that it is largely or even exclusively interpretative: that is, a data scientist looks at a big set of data, a light bulb goes off in her head, she has some insight, and then acts on that insight.
The reality is data science is much more than that. And most of data science is a combination of (a) getting data ready for analysis, (b) hypothesis testing, and (c) figuring out what to do with the results of a and b. That is, data science in practice is generally not some artesenal genius staring at a table of numbers until “insight” magically occurs, but rather a lot of work, a lot of structured theories which can be confirmed or falsified, and a lot of imagination applied to the task of implementation. Good, effective data scientists, in practice, are often not those with the most cutting-edge algorithm, but rather those who are able to get the right data and ask the right questions.
In other words, data goes through a whole lifecycle of which analysis is just a small part. What is the data lifecycle?
Here’s how we conceptualize it:
- Observation
- Problem identification and definition
- Question formation
- Hypothesis generation
- Data collection
- Data processing
- Model building / hypothesis testing
- Operationalization
- Communication / dissemination
- Action
- Observation
Does the above look a lot like the sceintific method? That’s because it basically is. The main differences are (a) “data processing” (which in reality takes up most of any data scientist’s time), (b) the bias towards action, and (c) the iterative / looped nature of the lifecycle.
Data science ‘in the wild’
Enough theory - let’s talk about what data scientists are actually doing in the real world.
Data scientists are working on a ton of problems. Some examples include:
- Targeted advertising
- Dynamic airline pricing
- Social media feed optimization
- Making video games more fun / addictive
- Identifying and filtering inappropriate content on the internet
- Search autocomplete
- Automating identification of credit card fraud
- Facial recognition
- Voice recognition
- Filtering spam
- Autocorrect
- Virtual assistants
- Preventive maintenance at nuclear facilities
- Identifying tax evaders
- Identifying disease through imagery
- Improving chemotherapy dosage
- Quantifying the likelihood of recedivism to prevent over-incarceration
- Surveilling emergency rooms to predict disease outbreaks
- Improve matchmaking systems (liver transplants, love, etc.)
- Detecting fake news
- Predictive policing
Why R?
This course is largely about learning to do, and will largely use R. R is not the only tool in the data scientists’ toolbox, but it’s a good one, is extremely popular, has a larger community and user base, and can be applied to many fields.
What are some of the other tools and languages used by data scientists? There are plenty (and we won’t cover them here). But the main reason we choose R for this course is the fact that it is open-source and free. This matters because…
The reproducibility crisis
There is a crisis in science (and data science): the reproducibility crisis (also known as the replication crisis). This refers to the fact that many scientific studies have been impossible to reproduce, calling into question the validity of those studies’ findings. This is a big deal: if a significant part of science is wrong then what do we know, how can we be sure what we know is right, and how can we separate the wheat from the chaff?
Because of this crisis, there has emerged a much needed move to make all science “reproducible”. This means making sure that someone else can copy what you did, and get the same results. This is important for identifying scientific fraud, of course, but also for helping us to overcome human bias, mistakes, wishful thinking, etc. Reproducibility is not just a “nice-to-have”; in modern science (and data science), it’s a “must”.
Good data science must be reproducible. And reproducible science means using tools that others can easily use, and methods that others can easily copy. Programming languages like R and Python are ideal for this.
In this course, we’ll focus on reproducible research, literate programming, documentation, and other components of data science (and research in general) which ensure that (a) our methods and findings can be easily sanity-tested by others, and (b) we set ourselves and our projects’ up for future collaborations, hand-offs, and expansion.